Lecture 2. Basic machine learning models
HTML Slides
 │ PDF Slides
│ PDF Slides
 │ Demo code on GitHub
│ Demo code on GitHub

Topic overview#
- Some common machine learning tasks and models
- Evaluating model performance
- Limitations and assumptions
Resources used:
- Feature Engineering Chapter 1
- Introduction to Machine Learning with Python. Available at MRU Library
- Scikit-learn User Guide
- Hands on Machine Learning with Scikit-Learn and Tensorflow/PyTorch. Available at MRU Library
Machine learning#
- To appropriately process the data, we need to know why we are doing it and what assumptions we’re making
- Modern machine learning toolkits (such as scikit-learn) are so easy to use, they’re easy to use inappropriately
- Goal: just enough understanding to use basic models responsibly
Why are we processing data?#

- No reinforcement learning in this course, sorry
A selection of common models#
Supervised#
- Linear/logistic regression
- Decision trees
- Support vector machines
Unsupervised#
- K-means clustering
- Principle component analysis
No free lunch#
- A theory-heavy paper in 1996 showed that there is no one machine learning algorithm that excels in all situations
- Subsequent work has confirmed this, e.g. a 2018 analysis
- Tree-based methods, particularly gradient boosted trees tend to outperform other algorithms the most, but still have limitations
- What does it mean to “outperform”?
Model evaluation: Classification#
True positive: predicted positive, label was positive ($TP$) ✔️
True negative: predicted negative, label was negative ($TN$) ✔️
False positive: predicted positive, label was negative ($FP$) ❌ (type I)
False negative: predicted negative, label was positive ($FN$) ❌ (type II)
Accuracy is the fraction of correct predictions, given as:
$$\mathrm{accuracy} = \frac{TP + TN}{TP + TN + FP + FN}$$
Precision and recall#
Precision: Out of all the positive predictions, how many were correct? $$\mathrm{precision} = \frac{TP}{TP + FP}$$
Recall: Out of all the positive labels, how many were correct? $$\mathrm{recall} = \frac{TP}{TP + FN}$$
Specificity: Out of all the negative labels, how many were correct? $$\mathrm{specificity} = \frac{TN}{TN + FP}$$
Confusion matrix#
| Predicted Positive | Predicted Negative | |
|---|---|---|
| True Positive | TP | FN |
| True Negative | FP | TN |
- The axes might be reversed, but a good predictor will have strong diagonals
- There’s also the F1 score, or harmonic mean of precision and recall: $$F1 = 2 \cdot \frac{\mathrm{precision} \cdot \mathrm{recall}}{\mathrm{precision} + \mathrm{recall}}$$
ROC Curves#
The receiver operating characteristic curve is a plot of the true positive rate (recall or sensitivity) vs. false positive rate (1 - specificity) as the detection threshold changes
The diagonal is the same as random guessing
A perfect classifier would hug the top left corner
Fun fact: the name comes from WWII radar operators, where true positives were airplanes and false positives were noise
Classification model: Support Vector Classifier#
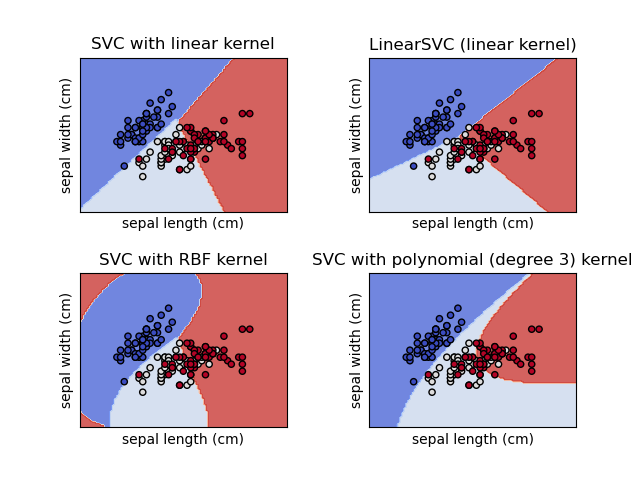
- Linear model that finds vector(s) to best separate classes
- “Kernel trick” allows for nonlinear boundaries
- Check out the SVM Appendix of Hands-on Machine Learning by Aurélien Geron for more info